
Introduction
Recent developments in the area of Artificial Intelligence (AI), specifically the advancement of deep learning and increased computing power, have made autonomous driving feasible for the first time. This blog describes the transition from code-centric algorithms into data-centric algorithms that are necessary for deep learning. Though the results achieved by these new methods are significant, they require large amounts of training data and raise problems around the storing and transmission of data from the autonomous vehicles.
Deep Learning
Deep learning can be defined as a group of machine learning methods that understand features from training data without the need for manual features or model engineering. Inspired by the way humans learn about the world, deep learning supports supervised, semi-supervised or unsupervised learning.
Deep Neural Networks are used to implement deep learning, which are based on Neural Network algorithms that have been known for years. Advancements in computer power along with the availability of large amounts of data have fueled the popularity of deep learning, specifically for tasks such as image processing, object detection and speech recognition. By using deep learning, intricate structures in large data sets are discovered during the learning process.
Deep Learning and AI
The figure below illustrates the relation between the various Artificial Intelligence algorithms and the reliance on coding vs. data.

This is just for illustrative purposes, it does not accurately reflect the scale.
Artificial Intelligence (AI) is any method that enables computers to mimic human intelligence using logic, if-then-rules, decision trees, and machine learning (including deep learning). Machine Learning (ML) is a subset of AI that includes statistical methods and neural networks (including deep learning) that enables computers to improve task performance through a process of learning from “experience”.
Traditional computer science algorithms (such as sorting, searching, decision trees, state machines, etc.) require coding of the individual tasks and cases, and rely less on data. With machine learning (and deep learning algorithms in particular) the data becomes much more dominant and important than coding.
ImageNet ‘09: Transformational Moment
Initially, machine learning researchers struggled with the challenge of overfitting or overgeneralization. Overfitting is when an algorithm can only work with data like what it has been trained with and cannot understand more general examples. The other end of the spectrum is overgeneralizing, where the model doesn’t detect the right patterns between the data. The solution to both issues is to provide more real-world (and non-biased) training examples.
The breakthrough came in 2009 when a group of researchers (setting a goal to “map out the entire world of objects”) published the ImageNet database containing millions of real images. The images are manually annotated (bounding boxes of objects) and categorized (there are over 20 thousand categories).
The creation of this database and the advent of newly advanced methods to train deep neuron networks resulted in an industry-wide artificial intelligence boom. In just a few years, object classification in the ImageNet dataset rose from 71.8% to 97.3%, surpassing human abilities and effectively proving that bigger data leads to better decisions.
AI in Autonomous Driving
The figure below illustrates the high-level component architecture of autonomous vehicles and the areas where AI is currently used.

Most car makers follow this architecture, with a system broken into separate components that perform sensor fusion, object detection and maneuver planning. However, there is also a discussion (mostly in academia) about creating an end-to-end deep learning system where object detection and control decision making is combined into a single deep learning module, i.e. something similar to the way humans operate. This module might also include sensor fusion, which is currently typically done using statistical models such as Kalman filter.
The perception module shown in the diagram is where deep learning is extensively used.
Large Amounts of Data Are Needed
Deep learning components need to be trained with a large quantity of data to improve performance. While other machine learning algorithms typically reach a plateau even if more training data is provided, deep learning algorithms continue to improve and scale better. This is illustrated in the figure below.
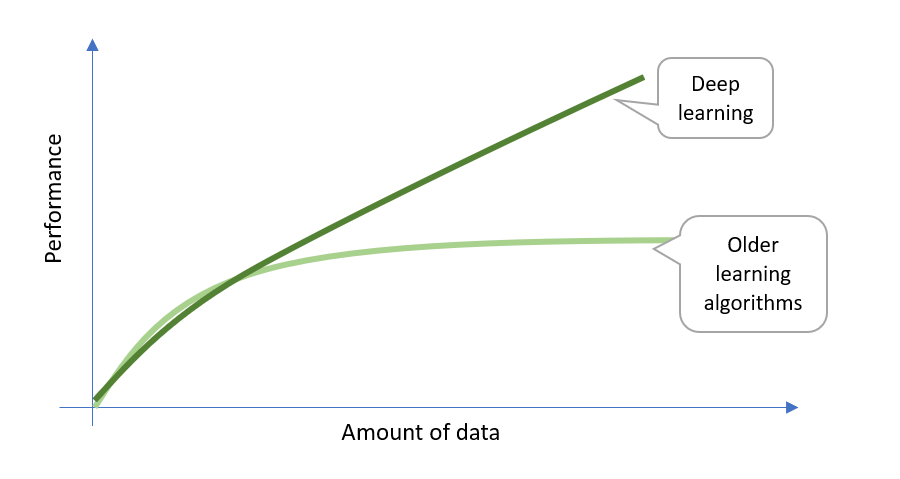
Although deep learning can be trained in an unsupervised way, currently most of the benefits from deep learning come from supervised learning, i.e. algorithms trained with labeled data.
Data Annotation Problem
Training-labeled data requires a combination of raw input data and corresponding annotations (a.k.a labels). The annotations are typically provided by a human and show and categorize where objects are in the input data (e.g. video frame). This information is fed to the deep learning algorithm during the training process. As a result, the algorithm adjusts the internal weight of various neural network layers, and with enough data can discover structure and patterns in the input data.
Producing annotated data from raw sensor information (such as video stream) is a time-consuming process, especially when sensor data comes not only from cameras, but other sensors such as LiDARs. The algorithm requires correct labels to be provided for every frame of data.
Some companies are providing tools to assist with the labeling process. Such tools might utilize AI to track already labeled objects across multiple frames and assist the human operator in marking the objects. Still, this process is time consuming and typically requires trained operators.
Data-Annotation-as-a-Service companies have recently sprung up to meet that need. These services typically use a network of freelancers to perform the process. Anecdotally, generic crowdsourcing platforms such as Amazon’s Mechanical Turk don’t seem work too well, as they produce data with a high degree of error, which is detrimental for the machine learning process. Annotation of vehicle generated data (especially from sensors like LiDAR) requires specialization and training.
New solutions have suggested automated labelling methods using stronger AI (running on powerful cloud hardware) that is self-trained on the millions of publicly available data (such as YouTube videos).
How Much Data is Needed?
According to a RAND report published in 2016, autonomous vehicles would have to be driven hundreds of millions of miles (and, under some scenarios, hundreds of billions of miles) to create enough data that clearly demonstrates their safety. As a result, it would take existing fleets of autonomous test vehicles decades to record sufficient miles to adequately assess vehicle safety compared to human driven vehicles.
This means that alternative testing methods need to be developed that supplement road testing to accelerate the development and validation of autonomous vehicles. Such methods might include simulation, virtual testing, mathematical modelling, scenario testing, pilot studies, and others.
Testing is one side of the equation, and as discussed earlier, deep learning models are only as good as the data they are trained on. Numerous good examples are necessary for these models to be able to handle all scenarios. Collecting data for edge problems, which in the real world are unlimited, present the biggest challenge in potentially time consuming, expensive and dangerous data collection.
Simulation
Simulation is one approach that has been suggested for deep learning model training and autonomous vehicle validation. Simulation can augment real-world training data, and some researchers suggest the best approach is to combine data from test vehicles (high-resolution data), with lower resolution data (from real vehicles) and then simulate millions of miles of data to achieve billions of miles of test and training data.
The challenge is that if models are trained in simulation data they might not behave correctly in the real world, where factors like weather conditions, light conditions, random objects and real sensor characteristics might not have been accurately captured by the simulation environment. Relying on simulation data alone might create the “overfitting” problem described earlier, resulting in a car that is very good at driving in simulated environments but handles the real world very poorly. Current research suggests that a hybrid training approach using a combination of real data and simulated data (to cover edge case scenarios of weather conditions, pedestrians, etc.) produces better results than training exclusively on more limited real-data.
Virtual Worlds
Certain companies have begun providing simulation environments, some of which produce photo-realistic simulation with the ability to trigger multiple events and produce different weather conditions, and some can even simulate LiDAR data.
Naver Labs published its open source database (called Virtual KITTI) of photo-realistic synthetic video dataset, which contains 50 high-resolution monocular videos (21,260 frames) generated from five different virtual worlds in urban settings under different imaging and weather conditions. These videos are annotated for 2D and 3D multi-object tracking and at the pixel level with category, instance, flow, and depth labels.
Weather Simulation
Some researchers have proposed algorithms to simulate different weather conditions by modifying video images of existing real-world data. For example, in the recent paper “Semantic Foggy Scene Understanding with Synthetic Data” Christos Sakaridis, Dengxin Dai and Luc Van Gool propose a method of adding fog data to images by taking depth information into account. State-of-the-art Convolutional Neural Network (CNN) trained on such simulated data sets has been shown to perform significantly better with real world fog images.
Such methods can reduce the need to collect and annotate a large amount of real-world data with adverse weather conditions.
Human Motion Simulation
One of the difficulties in real world simulation is generating natural human motion, as no computer algorithms can currently synthesize such natural motion. To overcome this problem, companies are using motion capture, which is the process used in movies and games to record the actions of human actors and animate digital character models in 2D or 3D computer animations. Such recorded motion can then be used as a base for simulation.
Universitat Autònoma de Barcelona (UAB) recently released a procedural generative model of human action videos (http://adas.cvc.uab.es/phav/) with more than 40,000 high-res videos of various human actions that can be used for simulation.
Data Tsunami
Recent estimates suggest that self-driving car sensors (cameras, radars, LiDARS, telematics) will produce 120 TB of data per month per car. If all 1.4 billion vehicles currently on the road become autonomous, the total amount of data generated will be staggering. In comparison, 2.5 billion smartphone users currently use approximately 2 GB data per month each. The data from the autonomous vehicles is multiple thousand times more than that of a typical smartphone user
This presents big challenges for the car companies across several areas. These include hardware challenges to store the data in the vehicle and the even bigger challenge of sending that data back to the cloud for analysis, testing and additional training. This data is needed to overcome the billion-mile autonomous driving challenge; thus, data from consumer vehicles must somehow be made available for additional validation and algorithm training. Relying only on specially equipped test vehicles is not practical to collect enough data in the required timeframe.
Even with the upcoming 5G infrastructure, transferring such massive amounts of data will most likely prove prohibitively expensive. To solve this problem, alternate data compression solutions have been proposed that send only lower-resolution data from end-user vehicles and augment that data with high-resolution data from specially equipped test vehicles.
Conclusion
Recent developments in deep learning algorithms and AI have put autonomous vehicles within reach. However, there are still many unanswered questions, most significantly around data.
It is hard to predict the behavior of machine learning algorithms. By their very nature, they are opaque and must be validated and tested with a large data set. But how much data is enough to say that a vehicle is safe for our roads? Should vehicles be tested for a billion miles before they are deemed safe? The automotive industry and government regulators don’t have an answer yet, and there is no minimum criteria or agreement on what a representative test environment should be.
In the next few years, as more autonomous vehicles are being tested on the roads, it will become clear if they are ready for prime time or not. One thing that is already abundantly clear is that data plays a very important role in modern AI and autonomous vehicles. To reduce cost and create a common testing and certification environment, the companies involved will need to share more data between each other, and a standard should be developed for vehicle sensor data and annotation that can be used to share this data for deep learning model training and validation.

